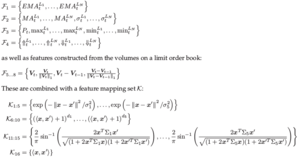
Currency Forecasting using Multiple Kernel Learning with Financially Motivated Features
New Directions in Multiple Kernel Learning, NIPS 2010
Multiple Kernel Learning (MKL) is used to replicate the signal combination process that trading rules embody when they aggregate multiple sources of financial information when predicting an asset’s price movements. A set of financially motivated kernels is constructed for the EURUSD currency pair and is used to predict the direction of price movement for the currency over multiple time horizons. MKL is shown to outperform each of the kernels individually in terms of predictive accuracy. Furthermore, the kernel weightings selected by MKL highlights which of the financial features represented by the kernels are the most informative for predictive tasks.

Multiple Kernel Learning on the Limit Order Book
Workshop on Applications of Pattern Analysis 2010
Simple features constructed from order book data for the EURUSD currency pair were used to construct a set of kernels. These kernels were used both individually and simultaneously through the Multiple Kernel Learning (MKL) methods of SimpleMKL and the more novel LPBoostMKL to train multiclass Support Vector Machines to predict the direction of future price movements. The kernel methods outperformed a trend following benchmark both in their predictive ability and when used in a simple trading rule. Furthermore, the kernel weightings selected by the MKL techniques highlight which features of the EURUSD order book are the most informative for predictive tasks.
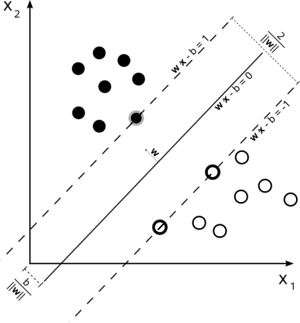
Support Vector Machines Explained
Tutorial Paper
This document has been written in an attempt to make the Support Vector Machines (SVM) as simple to understand as possible for those with minimal experience of Machine Learning. It assumes basic mathematical knowledge in areas such as calculus, vector geometry and Lagrange multipliers. The document has been split into Theory and Application sections so that it is obvious, after the maths has been dealt with, how to actually apply the SVM for the different forms of problem that each section is centred on.

Relevance Vector Machines Explained
Tutorial Paper
This document has been written in an attempt to make Tipping’s Relevance Vector Machines (RVM) as simple to understand as possible for those with minimal experience of Machine Learning. It assumes knowledge of probability in the areas of Bayes’ theorem and Gaussian distributions including marginal and conditional Gaussian distributions. It also assumes familiarity with matrix differentiation, the vector representation of regression and kernel (basis) functions.

The Kalman Filter Explained
Tutorial Paper
The aim of this document is to derive the filtering equations for the simplest Linear Dynamical System case, the Kalman Filter, outline the filter’s implementation, do a similar thing for the smoothing equations and conclude with parameter learning in an LDS (calibrating the Kalman Filter).